I’m running a calculation that parallelizes well using both MPI and OpenMP. While reading online, it occurred to me that I might gain speedup with a GPU node. How can I estimate the potential benefit? And is it possible to monitor GPU usage once it’s been allocated?
You’ll have to optimize your code to take advantage of the GPU cores. (exactly how will vary by language) Monitoring will depend on what brand of GPU you have. Take a look at this:
https://askubuntu.com/questions/387594/how-to-measure-gpu-usage
How much benefit will depend on how well the code is optimized to run on the core. Best test would be to re-write it and try to run the same size sample and see how long it takes.
GPUs are really good at SPMD algos - single process, multiple data, wherein you do the same operation on zillions of input data. Matrix math, image processing (kind of the same thing), some Machine learning, approaches, shift-add hash operations on multiple strings/reads as per some bioinfo approaches. If you interrupt these operations with logic (if, while, comparisons, subroutine calls), the magnitude of improvement drops tremendously. So you have to decide whether your input data and analytical flow maps well to GPUs. In many cases, small amounts of an analytical flow can be tremendously improved, but optimization of 5% of your entire flow to zero only saves you 5%. Beware premature optimization. ![]()
You can see what your Nvidia GPUs are doing with the nvidia-smi utility which will tell you various stats about the state and activity of the GPU. I’ve no idea how to do this with ATI cards.
# nvidia-smi
Tue Jun 11 07:53:46 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.66 Driver Version: 384.66 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 1080 Off | 00000000:02:00.0 Off | N/A |
| 27% 40C P0 39W / 180W | 0MiB / 8114MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 1080 Off | 00000000:03:00.0 Off | N/A |
| 27% 41C P0 39W / 180W | 0MiB / 8114MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 1080 Off | 00000000:83:00.0 Off | N/A |
| 27% 41C P0 39W / 180W | 0MiB / 8114MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Note also that many schedulers (SGE and derivatives at least) have trouble scheduling jobs for individual GPUs and sophisticated operations with them - suspending, moving, checkpointing jobs involving GPUs. If you’re not using a cluster, then this will have no impact, but if your jobs are large enough that they might migrate to a cluster, then this is a consideration.
I’ve seen some reports that overall, the total cost for GPUs vs the speed-up is about the same as for CPUs, obviously with some exceptions that are exactly matched for GPUs. The upside for buying CPUs is that they can be used for general purpose computing without any re-coding.
The easy test is to profile your code, see where the highest utilization is, and see if that code is amenable to re-coding for a GPU. If it is, get theyself a cheap gaming GPU and see how easy re-coding in CUDA is, and see what the overall speedup is.
1 Like
I’ve only tested this on our Cluster (nvidia I think) but I added a gpu task to watchme:
Scroll down the page to the “Run on the Fly, Command Line” section. If you are using Python, you can also try out the decorator. Open an issue if you run into any trouble!
First I would ask whether or not the code can already use a GPU…or are you going to add CUDA and/or OpenACC? (In which case…yikes!)
So this only answers
And is it possible to monitor GPU usage once it’s been allocated?
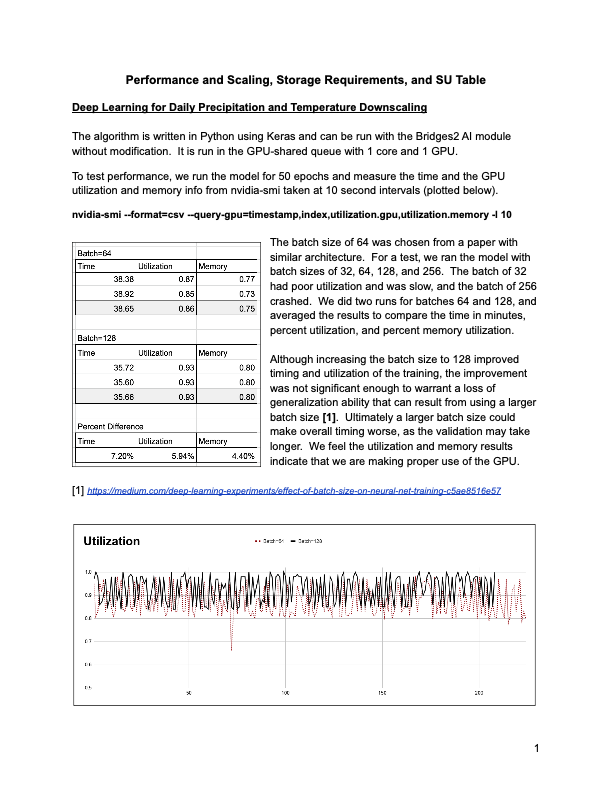
Rajanie Prabha at PSC was assigned as ECSS consultant for our machine learning project. I was writing an XRAC and had no idea how to monitor and access GPU utilization. She gave us this command to run during the batch job (you would redirect output to a file). This was done on PSC, Bridges2, which uses SLURM:
nvidia-smi --format=csv --query-gpu=timestamp,index,utilization.gpu,utilization.memory -l 10
GPU resource wise, we found the utilization was slightly low and could be improved with a larger batch size, but science-wise, increasing the batch size would not be desirable.
Effect of Batch Size on Neural Net Training | by Daryl Chang | Deep Learning Experiments | Medium
Below is an image from my XRAC proposal to get an idea of how I organized the output from nvidia-smi. (I can send the pdf or other info on request.)